Gongfan Fang
Ph.D. Candidate | xML Lab | National University of Singapore.

Hi there! I'm Gongfan Fang, a final-year Ph.D. candidate at the xML Lab, National University of Singapore, supervised by Prof. Xinchao Wang (Presidential Young Professor). I received my B.Eng. (2019) and M.Eng. (2022) from the VIPA Lab, Zhejiang University, advised by Prof. Mingli Song.
I'm currently working on Efficient Large Language Models and GenAI, with emphasis on LLM Reasoning, Model Efficiency, and Diffusion Language Models. I'm also the creator and lead developer of Torch-Pruning, a top framework for accelerating foundation models, which has been intergated into many industrial products like NVIDIA TAO (See the ACK). During my PhD, I previously worked with the amazing DLER team at NVIDIA. And I was awarded the 2024 ByteDance Scholarship (10~15 recipients per year).
News
| May, 2026 | 🍺 Four papers were accepted to ICML’26. |
|---|---|
| Feb, 2026 | ☕️ Two papers were accepted to CVPR’26. |
| Jan, 2026 | 🥤 Three papers dParallel, SparseD and Invisible Safety Threat (Oral) were accepted to ICLR’26. |
Selected Publications
Google Scholar
-
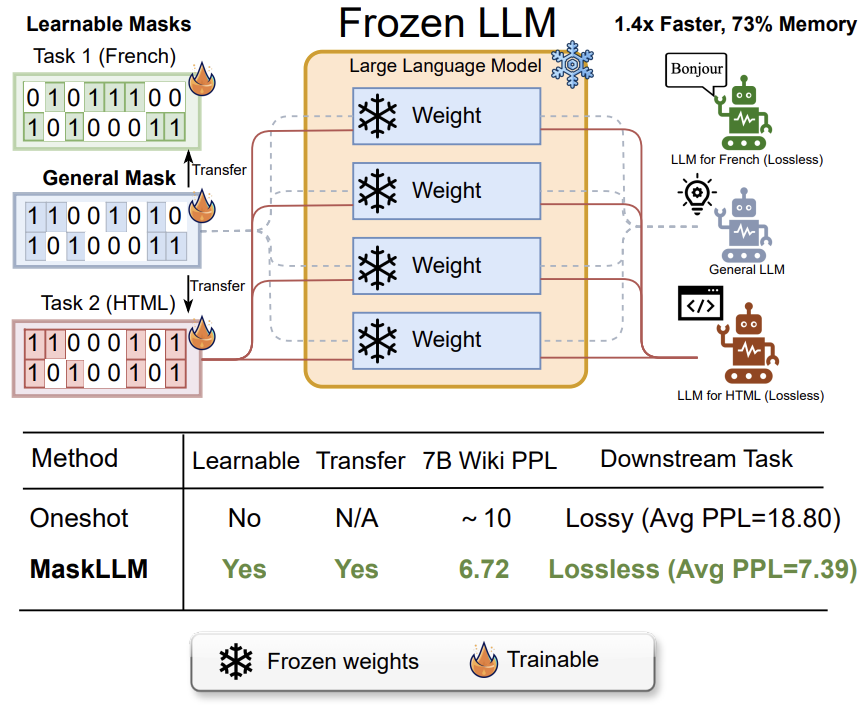
NeurIPS’24 MaskLLM: Learnable Semi-structured Sparsity for Large Language ModelsAdvances in Neural Information Processing Systems, 2024NVIDIA Research, National University of SingaporeNeurIPS’24 Spotlight (2%) | Post-training of Sparse LLMs | The First Scalable Algorithm for N:M Sparsity in LLMs | 1.5x Faster with 30%+ Memory Saving -
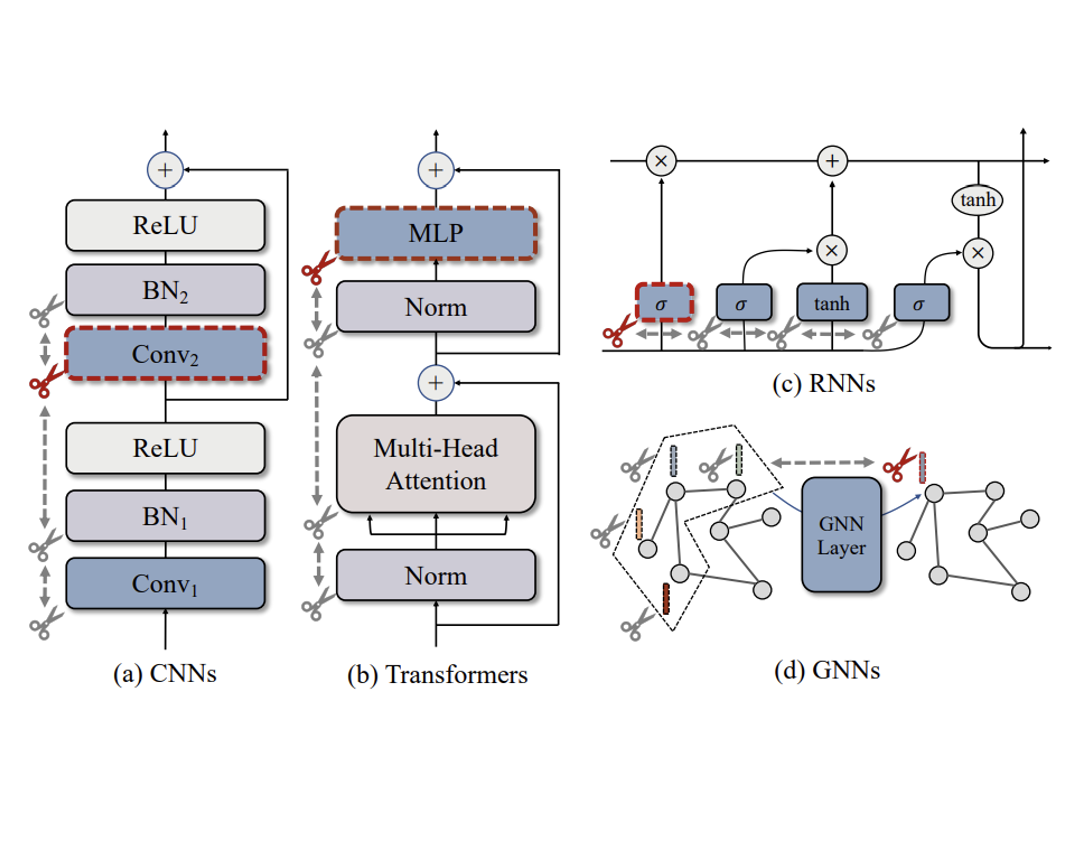
CVPR’23 DepGraph: Towards Any Structural PruningProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023National University of Singapore, Zhejiang University, Huawei500+ Citations, 3000+ Stars, 300,000+ Downloads | Github #Model-Compression Top-5 | Pruning of Foundation Models | Integrated in NVIDIA TAO




Education
2022.07 - 2026.06 - Ph.D. in Electrical and Computer Engineering, National University of Singapore.
2019.09 - 2022.04 - M.Eng. in Computer Science, College of Computer Science and Technology, Zhejiang University.
2015.09 - 2019.06 - B.S. in Computer Science, College of Computer Science and Technology, Zhejiang University.