@article{fang2025thinkless,title={Thinkless: LLM Learns When to Think},author={Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2025},}
ArXiv’25
In-Video Instructions: Visual Signals as Generative Control
@article{ma2025dkv,title={DKV-Cache: The Cache for Diffusion Language Models},author={Ma, Xinyin and Yu, Runpeng and Fang, Gongfan and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2025},}
NeurIPS’25
VeriThinker: Learning to Verify Makes Reasoning Model Efficient
@article{chen2025verithinker,title={VeriThinker: Learning to Verify Makes Reasoning Model Efficient},author={Chen, Zigeng and Ma, Xinyin and Fang, Gongfan and Yu, Ruonan and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2025}}
ArXiv’25
PixelThink: Towards Efficient Chain-of-Pixel Reasoning
Song Wang, Gongfan Fang, Lingdong Kong, Xiangtai Li, Jianyun Xu, Sheng Yang, Qiang Li, Jianke Zhu, and Xinchao Wang
arXiv preprint arXiv:2505.23727, 2025
Zhejiang University, National University of Singapore, Nanyang Technological University, Alibaba Group
@article{wang2025pixelthink,title={PixelThink: Towards Efficient Chain-of-Pixel Reasoning},author={Wang, Song and Fang, Gongfan and Kong, Lingdong and Li, Xiangtai and Xu, Jianyun and Yang, Sheng and Li, Qiang and Zhu, Jianke and Wang, Xinchao},journal={arXiv preprint arXiv:2505.23727},year={2025}}
@article{ma2025cot,title={CoT-Valve: Length-Compressible Chain-of-Thought Tuning},author={Ma, Xinyin and Wan, Guangnian and Yu, Runpeng and Fang, Gongfan and Wang, Xinchao},journal={arXiv preprint arXiv:2502.09601},year={2025}}
@article{fang2024tinyfusion,title={TinyFusion: Diffusion Transformers Learned Shallow},author={Fang, Gongfan and Li, Kunjun and Ma, Xinyin and Wang, Xinchao},journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2025},}
CVPR’25
Collaborative Decoding Makes Visual Auto-Regressive Modeling Efficient
@article{chen2024collaborative,title={Collaborative Decoding Makes Visual Auto-Regressive Modeling Efficient},author={Chen, Zigeng and Ma, Xinyin and Fang, Gongfan and Wang, Xinchao},journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2025}}
2024
NeurIPS’24
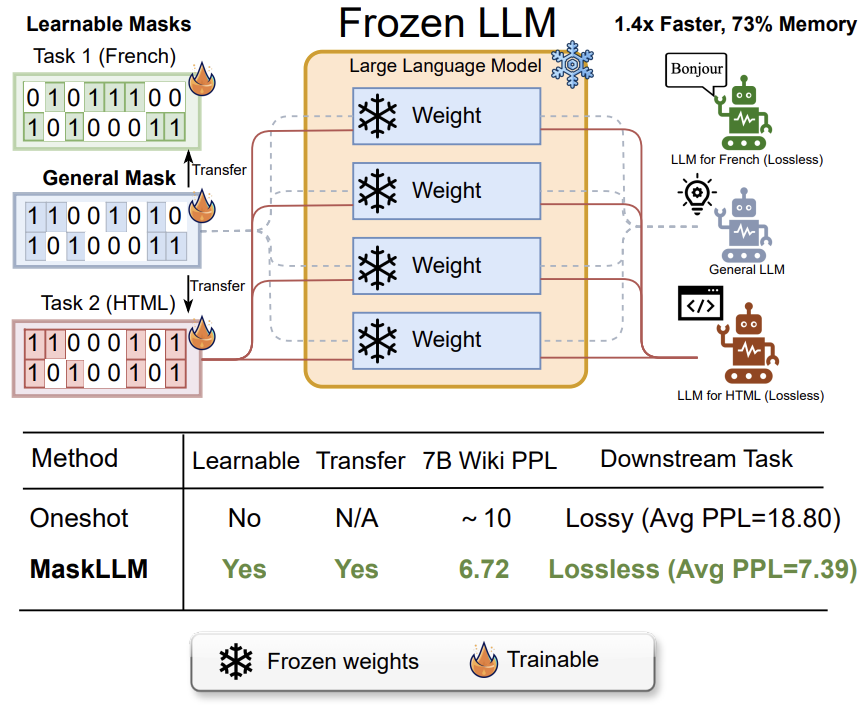
MaskLLM: Learnable Semi-structured Sparsity for Large Language Models
@article{fang2024maskllm,title={MaskLLM: Learnable Semi-structured Sparsity for Large Language Models},author={Fang, Gongfan and Yin, Hongxu and Muralidharan, Saurav and Heinrich, Greg and Pool, Jeff and Kautz, Jan and Molchanov, Pavlo and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2024},}
NeurIPS’24
Remix-DiT: Mixing Diffusion Transformers for Multi-Expert Denoising
@article{fang2024remixdit,title={Remix-DiT: Mixing Diffusion Transformers for Multi-Expert Denoising},author={Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2024}}
@article{fang2024isomorphic,title={Isomorphic Pruning for Vision Models},author={Fang, Gongfan and Ma, Xinyin and Mi, Michael Bi and Wang, Xinchao},journal={European Conference on Computer Vision},year={2024}}
NeurIPS’24
AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising
@article{chen2024asyncdiff,title={AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising},author={Chen, Zigeng and Ma, Xinyin and Fang, Gongfan and Tan, Zhenxiong and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2024}}
NeurIPS’24
Learning-to-Cache: Accelerating Diffusion Transformer via Layer Caching
@article{ma2024learning,title={Learning-to-Cache: Accelerating Diffusion Transformer via Layer Caching},author={Ma, Xinyin and Fang, Gongfan and Mi, Michael Bi and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2024}}
@article{chen20230,title={SlimSam: 0.1\% Data Makes Segment Anything Slim},author={Chen, Zigeng and Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},journal={Advances in Neural Information Processing Systems},year={2024}}
@inproceedings{ma2023deepcache,title={DeepCache: Accelerating Diffusion Models for Free},author={Ma, Xinyin and Fang, Gongfan and Wang, Xinchao},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2024},}
InterSpeech’24
LiteFocus: Accelerated Diffusion Inference for Long Audio Synthesis
@article{tan2024litefocus,title={LiteFocus: Accelerated Diffusion Inference for Long Audio Synthesis},author={Tan, Zhenxiong and Ma, Xinyin and Fang, Gongfan and Wang, Xinchao},journal={Conference of the International Speech Communication Association},year={2024}}
@inproceedings{fang2023depgraph,title={DepGraph: Towards Any Structural Pruning},author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},pages={16091--16101},year={2023},}
NeurIPS’23
LLM-Pruner: On the Structural Pruning of Large Language Models
@inproceedings{ma2023llmpruner,title={LLM-Pruner: On the Structural Pruning of Large Language Models},author={Ma, Xinyin and Fang, Gongfan and Wang, Xinchao},booktitle={Advances in Neural Information Processing Systems},year={2023},}
@inproceedings{fang2023structural,title={Structural Pruning for Diffusion Models},author={Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},booktitle={Advances in Neural Information Processing Systems},year={2023}}
2022
AAAI’22
Up to 100x Faster Data-free Knowledge Distillation
Gongfan Fang, Kanya Mo, Xinchao Wang, Jie Song, Shitao Bei, Haofei Zhang, and Mingli Song
Proceedings of the AAAI Conference on Artificial Intelligence, 2022
@inproceedings{fang2022up,title={Up to 100x Faster Data-free Knowledge Distillation},author={Fang, Gongfan and Mo, Kanya and Wang, Xinchao and Song, Jie and Bei, Shitao and Zhang, Haofei and Song, Mingli},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},volume={36},number={6},pages={6597--6604},year={2022}}
IJCAI’22
Prompting to Distill: Boosting Data-Free Knowledge Distillation via Reinforced Prompt
@article{ma2022prompting,title={Prompting to Distill: Boosting Data-Free Knowledge Distillation via Reinforced Prompt},author={Ma, Xinyin and Wang, Xinchao and Fang, Gongfan and Shen, Yongliang and Lu, Weiming},journal={Proceedings of International Joint Conference on Artificial Intelligence},year={2022}}
TIP’23
Knowledge Amalgamation for Object Detection with Transformers
Haofei Zhang, Feng Mao, Mengqi Xue, Gongfan Fang, Zunlei Feng, Jie Song, and Mingli Song
@article{zhang2022knowledge,title={Knowledge Amalgamation for Object Detection with Transformers},author={Zhang, Haofei and Mao, Feng and Xue, Mengqi and Fang, Gongfan and Feng, Zunlei and Song, Jie and Song, Mingli},journal={IEEE Transactions on Image Processing},year={2022}}
2021
NeurIPS’21
Mosaicking to Distill: Knowledge Distillation from Out-of-Domain Data
Gongfan Fang, Yifan Bao, Jie Song, Xinchao Wang, Donglin Xie, Chengchao Shen, and Mingli Song
Advances in Neural Information Processing Systems, 2021
@article{fang2021mosaicking,title={Mosaicking to Distill: Knowledge Distillation from Out-of-Domain Data},author={Fang, Gongfan and Bao, Yifan and Song, Jie and Wang, Xinchao and Xie, Donglin and Shen, Chengchao and Song, Mingli},journal={Advances in Neural Information Processing Systems},volume={34},pages={11920--11932},year={2021}}
IJCAI’21
Contrastive Model Inversion for Data-free Knowledge Distillation
Gongfan Fang, Jie Song, Xinchao Wang, Chengchao Shen, Xingen Wang, and Mingli Song
Proceedings of International Joint Conference on Artificial Intelligence, 2021
@article{fang2021contrastive,title={Contrastive Model Inversion for Data-free Knowledge Distillation},author={Fang, Gongfan and Song, Jie and Wang, Xinchao and Shen, Chengchao and Wang, Xingen and Song, Mingli},journal={Proceedings of International Joint Conference on Artificial Intelligence},year={2021}}
2020
EMNLP’20
Adversarial Self-Supervised Data-Free Distillation for Text Classification
Xinyin Ma, Yongliang Shen, Gongfan Fang, Chen Chen, Chenghao Jia, and Weiming Lu
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2020
@inproceedings{ma2020adversarial,title={Adversarial Self-Supervised Data-Free Distillation for Text Classification},author={Ma, Xinyin and Shen, Yongliang and Fang, Gongfan and Chen, Chen and Jia, Chenghao and Lu, Weiming},booktitle={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing},pages={6182--6192},year={2020}}
2019
Preprint’19
Data-free Adversarial Distillation
Gongfan Fang, Jie Song, Chengchao Shen, Xinchao Wang, Da Chen, and Mingli Song
@article{fang2019data,title={Data-free Adversarial Distillation},author={Fang, Gongfan and Song, Jie and Shen, Chengchao and Wang, Xinchao and Chen, Da and Song, Mingli},journal={arXiv preprint arXiv:1912.11006},year={2019}}